Serverless Computing provides an interesting compute paradigm with significant advantages in certain situations.
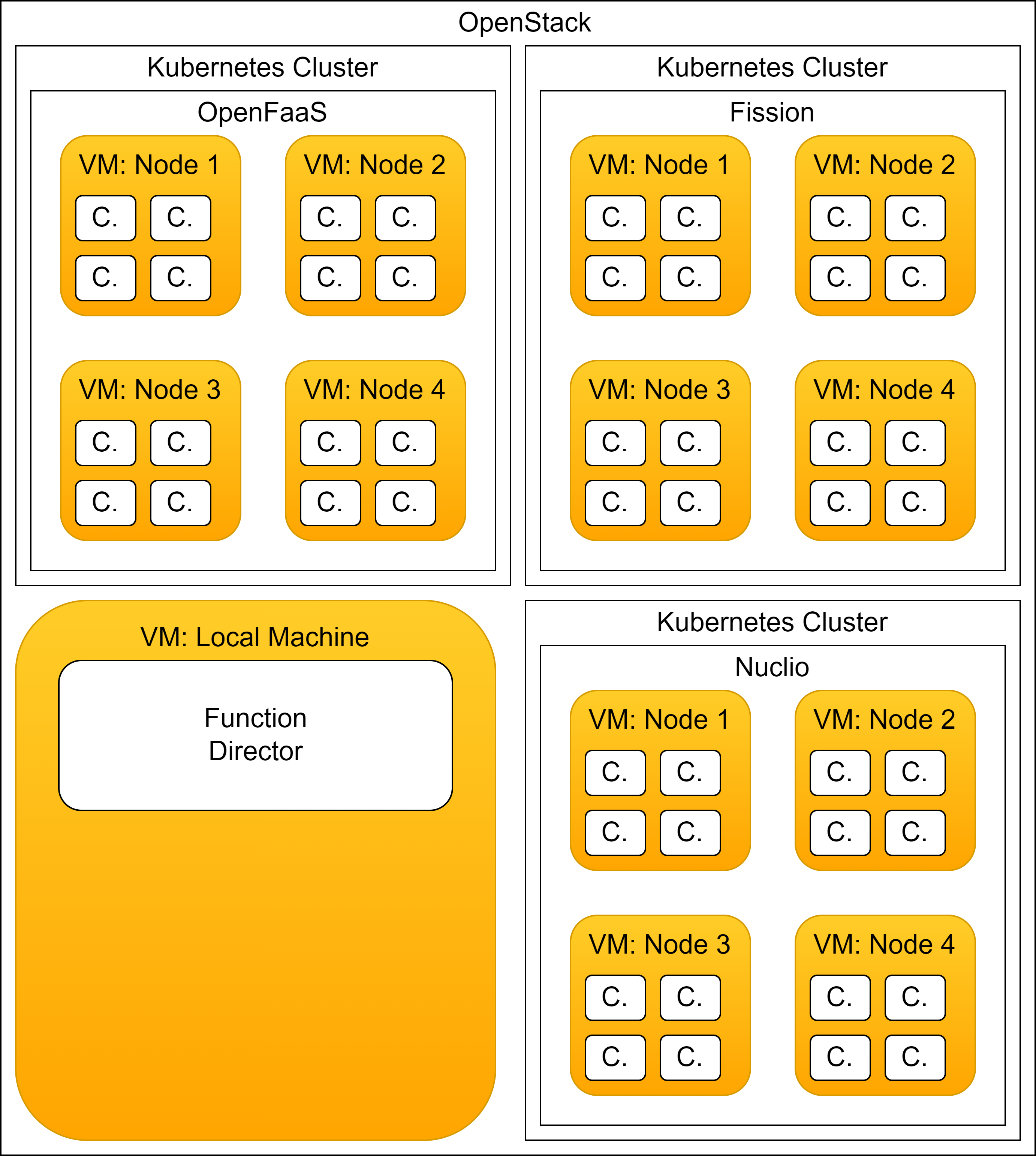
In my Master’s thesis I had studied the performance of multiple open source serverless runtimes in comparison.
Specifically, I had taken a closer look at OpenFaaS and Nuclio.
While the thesis stands for itself, I want to note a few takeaways here that arose to me while working on this.
On the Serverless Researchfield
The research field itself, at least at the time of doing the literature search, was heavily focused on AWS Lambda such that one third or up to half of the papers I looked through studied AWS Lambda or build on top of it.
This became a personal grudge for me as AWS Lambda is a closed source solution only available on hardware provided via AWS, which meant that the research conducted is difficult or impossible to reproduce.
Moreover, AWS might at any point change the service by updating the software or hardware.
Nevertheless, this does not negate the value of research into serverless via AWS Lambda but limits its comparability.
For instance, verifying whether a new approach to employ AWS Lambda to process a set of workloads is better than another presented in a previous publication requires to rerun the measurements from the previous study as well as the exact performance numbers cannot be compared anymore.
On Serverless Function Portability
Another notable property of the state of serverless runtimes was that there is no agreed upon API standard.
A serverless function is typically expected to integrate with some form of calling interface defined by the runtime.
It is simplest form, a serverless function requires an input of an arbitrary type and will deliver an output, also of arbitrary type.
Through programming languages such as Python or JavaScript, this was easily achieved as the functions could be dynamically loaded.
Even in Go through its plugin feature, this was possible.
Still, this did not work for all programming languages such as C that deliver functions as pre-compiled binaries that operate through input and output streams.
Between the different serverless runtimes, the interface that a had to be implemented for a function was different every single time despite the internal operation doing the same.
This can be considered a form of vendor lock-in as moving a large amounts of serverless functions between runtimes requires adjusting the interface for each function.
On the Usefullnesss of Serverless Computing
So knowing all that I asked myself, how useful is serverless computing?
As serverless runtimes handle all the overhead of scaling, routing and monitoring serverless functions, the functions themselves can be extremely lightweight and kinda have to be as it is assumed that serverless functions can be ready in less than a second.
So if one has multiple such small function that need to be available, serverless is a valid approach.
One could even conceive of writing an application that splits itself into many serverless functions such that when part of that application is under load, it can be scaled up automatically.
However, this puts very specific requirements on the type of scalability that the application must support as individual calls to such a serverless function must be fully independent from each other.
Moreover, the scalability is also limited by the performance as making calls to serverless functions always requires going out of the control flow of the application and going on the network to reach out to another part of the application via the serverless runtime.
What this effectively does is that instead of performing operations locally, the control flow has to switch to another process via the network, transporting data over with it.
For large enough applications or data sets this might be unavoidable but serverless runtimes are often naïve with respect to data locality such that data is copied over and over.
When comparing this to a tool such as MPI, which enables tight control over communication and data exchange between processes, serverless tends to leave a lot of performance on the table.
Despite these performance limitations, serverless has its niche and it will be interesting to see if future developments improve the ease of employing serverless by unifiying APIs and optimizing function placement and routing.
For more information, please read my master’s thesis here: https://doi.org/10.25625/6gsjse
Related Posts
About Me

Dr. Jonathan Decker
Jonathan Decker takes the role of a system architect with a focus on designing systems that enable new and novel ways of utilizing Cloud and HPC resources, while also being efficient, secure and scalable.
Most notably, he strives to combine HPC with Kubernetes to get the best of both worlds.
Jonathan completed his PhD in 2025 via his work on Chat AI and its underlying AI inference platform, which now enables secure and sensitive access to AI services for students and researchers across Germany.
Moreover, in 2025, he served as the speaker of the PhD student representatives of the Georg-August-University of Göttingen.
Now he heads a team in the High-Performance Storage research group of Prof Kunkel while being in close collaboration with the GWDG.
There he handles research, supervision of PhD students and university teaching activities.