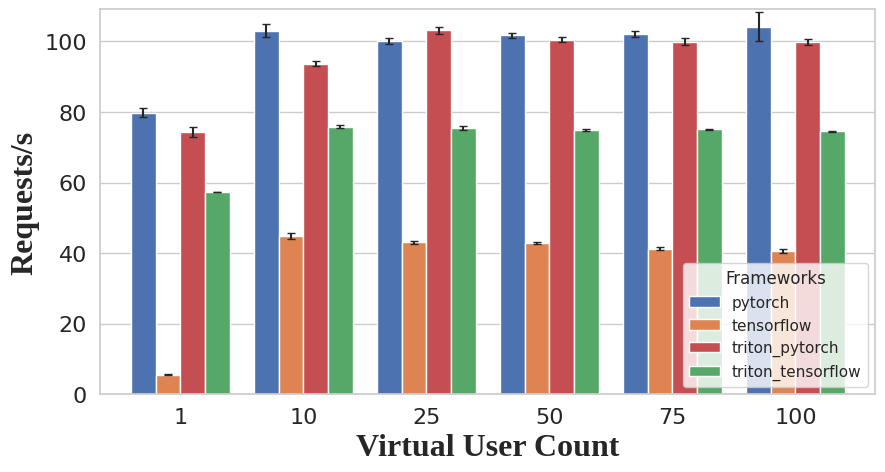
This paper covers a study on the performance of various machine learning model inference runtimes including Tenserflow Serving and PyTorch Serve as well as NVIDIA Triton with either of these as the backend.
The paper was written by Egi Brako based on his bachelor’s thesis, which he had written under my guidance and supervision.
As a lecturer it is amazing to one of your students go from writing their thesis to a scientific publication about it.
While this is not too uncommon for master’s theses, it is a rare and amazing feat to do so based on a bachelor’s thesis.
The paper itself compares the above mentioned inference runtimes for different types of machine learning models including image classification, speech recognition and text summarization.
The comparison is based on the throughput rate both for single and multi stream use cases as well as how the runtimes handle high amounts of simultaneous user requests.
Additionally, the study also considered the usability of each runtime based on how difficult or easy it was to operate during the experiments and how compatible it was with the different use cases.
The result of the study was that PyTorch Serve and NVIDIA Triton with PyTorch as its backend showed the strongest performance across all use cases.
However, PyTorch Serve has since been archived and is no longer being updated and therefore not recommended as security issues are not fixed anymore.
Therefore, employing NVIDIA Triton with PyTorch is recommended.
Nevertheless, it should be noted that while Tensorflow Serving showed the weakest performance, it is still actively being developed and improved such that the performance measured in the paper might not be representative of the newest Tensorflow Serving release.
To see all the details, it is recommended to read the paper, which can be found here: https://www.thinkmind.org/library/SCALABILITY/SCALABILITY_2024/scalability_2024_1_20_20010.html
Related Posts
About Me

Dr. Jonathan Decker
Jonathan Decker takes the role of a system architect with a focus on designing systems that enable new and novel ways of utilizing Cloud and HPC resources, while also being efficient, secure and scalable.
Most notably, he strives to combine HPC with Kubernetes to get the best of both worlds.
Jonathan completed his PhD in 2025 via his work on Chat AI and its underlying AI inference platform, which now enables secure and sensitive access to AI services for students and researchers across Germany.
Moreover, in 2025, he served as the speaker of the PhD student representatives of the Georg-August-University of Göttingen.
Now he heads a team in the High-Performance Storage research group of Prof Kunkel while being in close collaboration with the GWDG.
There he handles research, supervision of PhD students and university teaching activities.