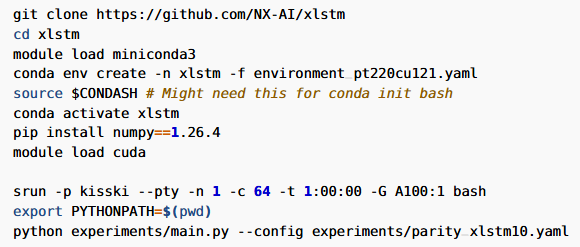
While Transformers1 have been the driving force between the rise of LLMs, before them, LSTM or Long Short-Term Memory2 has been one of the state-of-the-art machine learning model architectures.
However, it had short comings compared to Transfomers, which the inventor of LSTM, Sepp Hochreiter, sought to rectify with the introduction of xLSTM.
While Transformers are a powerful machine learning architecture, they are extremely resource hungry as their time and memory complexity is O(N²).
xLSTM on the other hand has time complexity O(N) and memory complexity O(1)3.
I have given this talk in our machine learning journal club after being invited to do so.
My research work is usually removed from the concrete implementation details of machine learning architectures, however, I was still interested and by accepting the invitation, I forced myself to dedicate time to investing this topic.
While the depth and perspective of the talk very much reflects my own view of the topic, they are still very useful to gain an overview of xLSTM and its surrounding technologies.
The full slides of the talk can be found here: Slides.
-
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N. and Kaiser, Lukasz and Polosukhin, Illia, (2023), “Attention Is All You Need”, arXiv, [Link to article]. ↩
-
Hochreiter, Sepp and Schmidhuber, Jürgen, (1997), “Long Short-Term Memory”, Neural Computation, 9, p1735–1780, [Link to article]. ↩
-
Beck, Maximilian and Pöppel, Korbinian and Spanring, Markus and Auer, Andreas and Prudnikova, Oleksandra and Kopp, Michael and Klambauer, Günter and Brandstetter, Johannes and Hochreiter, Sepp, (2024), “xLSTM: Extended Long Short-Term Memory”, arXiv, [Link to article]. ↩
Related Posts
About Me

Dr. Jonathan Decker
Jonathan Decker takes the role of a system architect with a focus on designing systems that enable new and novel ways of utilizing Cloud and HPC resources, while also being efficient, secure and scalable.
Most notably, he strives to combine HPC with Kubernetes to get the best of both worlds.
Jonathan completed his PhD in 2025 via his work on Chat AI and its underlying AI inference platform, which now enables secure and sensitive access to AI services for students and researchers across Germany.
Moreover, in 2025, he served as the speaker of the PhD student representatives of the Georg-August-University of Göttingen.
Now he heads a team in the High-Performance Storage research group of Prof Kunkel while being in close collaboration with the GWDG.
There he handles research, supervision of PhD students and university teaching activities.